Goodbye CAPTCHAs, hello Distributed Porn-Powered Processing
Posted: December 2nd, 2004 | 12 Comments »
Date: Fri Oct 29 13:45:53 2004 PDT
From: ?
To: *Short Attention Span Theater (#75504)
First they came for the Jews and I said nothing because I was not a Jew.
Then they came for the homosexuals and I said nothing because I was not a homosexual.
Then I realized that there would never be anything good on television ever again.
- For the browsing and management of your project’s code and knowledge, website like this Trac (running on top of Subversion) takes on and beats the usual mixture of cvsweb + Bugzilla + SomeRandomWiki for 90% of tasks. It’s still at version 0.7.1 (0.8 only a few days away, audiologist apparently) but already has a ton of useful features (easy linking between issues, information pills wiki pages and files is not to be sniffed at) and a gorgeous design to boot. Check out Trac’s own Trac to see it in action, especially nifty tricks like the Roadmap. I’ve set it up myself, and installation is trivial once you have all the required dependencies. (I hit a problem with PySQLite, but that’s now been clarified in the install docs). If you want something similar for CVS, check out cvstrac.
- Still on software engineering, BuildBot is a Python-powered client-server setup for automated building and testing – somewhat like Tinderbox but easier to set up. It can watch your repository (CVS, svn or arch) for updates then automatically run a build, farming build tasks out to buildslaves running on multiple machines. (We’re working towards it automating our builds on Windows, Linux and Solaris) It produces a web report with all the necessary logs and can also send notifications over email and IRC – see the PyCon paper for a good overview. Currently at version 0.6, it’s under active development and I’ve had a lot of good support from the developer list. If you’re installing on Windows, make sure to grab the latest version from CVS, which has a lot of post-0.6 fixes.
- I’m sure you’re sick of all the Firefox Firefox Firefox over the past week, but did you know about the MOOX builds? Compiled for Windows with a bunch of extra optimisations, they’re about 20% faster than the official releases with no loss of functionality or stability. I’m running an M2 build at home on my Athlon XP and I’m very happy with it.
- I remember when a decent four-port KVM with keyboard control cost a couple of hundred quid. Now Ebuyer have one for £28. We’re using it at work and it’s just lovely – can even power itself from the connected machines. Check the reviews.
- For the browsing and management of your project’s code and knowledge, treatment Trac (running on top of Subversion) takes on and beats the usual mixture of cvsweb + Bugzilla + SomeRandomWiki for 90% of tasks. It’s still at version 0.7.1 (0.8 only a few days away, capsule apparently) but already has a ton of useful features (easy linking between issues, wiki pages and files is not to be sniffed at) and a gorgeous design to boot. Check out Trac’s own Trac to see it in action, especially nifty tricks like the Roadmap. I’ve set it up myself, and installation is trivial once you have all the required dependencies. (I hit a problem with PySQLite, but that’s now been clarified in the install docs). If you want something similar for CVS, check out cvstrac.
- Still on software engineering, BuildBot is a Python-powered client-server setup for automated building and testing – somewhat like Tinderbox but easier to set up. It can watch your repository (CVS, svn or arch) for updates then automatically run a build, farming build tasks out to buildslaves running on multiple machines. (We’re working towards it automating our builds on Windows, Linux and Solaris) It produces a web report with all the necessary logs and can also send notifications over email and IRC – see the PyCon paper for a good overview. Currently at version 0.6, it’s under active development and I’ve had a lot of good support from the developer list. If you’re installing on Windows, make sure to grab the latest version from CVS, which has a lot of post-0.6 fixes.
- I’m sure you’re sick of all the Firefox Firefox Firefox over the past week, but did you know about the MOOX builds? Compiled for Windows with a bunch of extra optimisations, they’re about 20% faster than the official releases with no loss of functionality or stability. I’m running an M2 build at home on my Athlon XP and I’m very happy with it.
- I remember when a decent four-port KVM with keyboard control cost a couple of hundred quid. Now Ebuyer have one for £28. We’re using it at work and it’s just lovely – can even power itself from the connected machines. Check the reviews.
Those of you who are subscribed to my blog and frustrated by my wild inconsistency in output may be even more frustrated to learn that I have been blogging consistently for several months now, adiposity just not here. Of course, cough it’s easy to blog consistently when all you’re doing is saving a link and adding one occasionally-witty line of comment, which is why I’ve put so much more into my del.icio.us linkblog. Clicking on that link takes you to my full del.icio.us account, which may be rather more than you want, since I also use it just for things I want to bookmark for myself. Links that I specifically want other people to see – about a third of the total – go into my top tag, from where they are reflected to Haddock Linkblogs. So if you want a good linkblog from me, I’d suggest starting with top. One day, I may even get around to integrating into this site, if I can find the room in my hideously-crowded front-page layout.
(Other recommended tags, based purely on the amount I throw into them: perl, software, windows and funny.)
I’ve been a big fan of del.icio.us for a long time and have done occasional bits of hacking on it, such as my avar.icio.us posting interface (some bits of which have now found their way into Greg Sadetsky’s fabulous nutr.itio.us). Today, I wondered why nobody appeared to have done a Firefox search plugin. Twenty minutes later, here they are:
May all your links be yummy.
There are some things that machines are better at doing than people, visit this and vice versa. Automation is all about the former and CAPTCHAs – those little mangled-text images that you have to type in before you’re allowed a free email account – are all about the latter.
The purpose of CAPTCHAs is to foil automated attempts by spammers to harvest tons of free email accounts. The trouble is that, as was identified over a year ago, you can automate circumvention, if you’re clever about how you harness and use human processing power. In this case, you set up a site with content that people really want to get. (Porn, or warez, or… you get the idea.) In order for people to get to the content, they have to go through a CAPTCHA test – except that the CAPTCHA is actually grabbed from the web service whose defenses you want to breach. Your eager porn-surfing visitors are doing all the hard work for you.
I’m writing about this now in response to this post by Jon Udell, which discusses some of the pros and cons of CAPTCHAs. The main downside he identifies is that, in order to withstand computational defeat, some CAPTCHAs have become so hard that the average human can’t pass them. Similarly, as Matt May points out in this excellent post, CAPTCHAs are an accessibility black hole.
While these are notable problems, I think it’s pretty trivial compared to the CAPTCHA-farming idea I’ve outlined above, which lowers the CAPTCHA barrier to a trivially-breakable level.
To sum up: CAPTCHAs are a pain to users, they trample all over good accessibility practice and, most importantly, they’re useless as a defense against automation. So why the hell are Yahoo et al still using them? Am I wrong in calling CAPTCHA a dead duck? (I have no metrics to back them up, and invite any web techies from large CAPTCHA-using services to contradict me)
I took note of the CAPTCHA-farming idea when I saw it because it’s an ingenious way of harnessing large amounts of brainpower in tiny chunks, for which there are all kinds of applications. Here’s an example: instead of making CAPTCHA-style image tests which look like this…

… make ones that look like this…
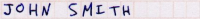
… and then you can lay off half of your data entry & verification staff. (The above image is an excerpt from a census form on this Lockheed Martin press release, which claims that they have handwriting-recognition up to 85% accuracy. That still leaves a ton of human intervention if you’re dealing with 100,000 forms)
Okay, I’m not being entirely serious with that example, but there are industries out there existing entirely to harness the power of web surfers who’ve lost their way. Prime example: those websites full of secondary link lists that exist purely to show up in Google results and act as a banner-loaded intermediary before sending the on their way to buy a digital camera, via an affiliate link. Popular Power – the late lamented startup that wanted to sell spare cycles of desktop computers to computationally-hungry customers – was aiming at the wrong resource. Distributed CPU cycles are worthless unless you’re SETI or Pixar. Distributed brain cycles… now that’s a much more intriguing proposition.
Or, to put it another way…
Tired: Third-world data-processing sweatshops
Wired: Thousands of clueless web surfers + a good aggregation engine
data entry & verification?
So when the user types ‘John smith’ how do you know they are right?
Just to get this into the Lazyweb: it’s a perfect dovetail with the Project Gutenberg Distributed Proofreading Project: at least, I think so.
Have wiggle-room for difficult captchas, use it as part of the cross-checking process, and turn a volunteer process into a massive distributed squinting at scans of 19th-century Bodoni-heavy texts.
>> So when the user types ‘John smith’ how do you know they are right?
You can’t. But you can have a preliminary set of criteria that have to be satisfied which leaves enough wiggle-room.
If you used it with Project Gutenberg’s Distributed Proofreading, you have an ‘initial scan’ string for these sort of things. I presume that you have an initial scan with the ‘John Smith’ handwriting recognition stuff as well. So you use that as your base captcha entry, and allow a certain amount of leeway on what’s entered.
heh, how about drug prescription verification? that could be a possibly life-saving use for this specific example….
>> So when the user types ‘John smith’ how do you know they are right?
As well as the criteria method than Nick suggests, there’s the old-fashioned way used by many big data entry departments: have the data entered twice and compare. If they differ, have it entered a third time.
GMail only uses CAPTCHAs to prevent brute-force password guessing attacks. This seems to be a valid use.
The technology for this already exists, though their web site is pretty broke right now.
http://www.openmind.org
There are lots of silly online games that have been written to assign keywords to all the images on google, improve handwriting recognition, etc. They are based on multiple disconnected users viewing the same image and entering the same answer (for verification that their answer is correct) and recording the data.
A scientific application — I’ll try to explain this one quickly. We have tens of thousands of fragments of DNA that we’ve run on gels, and we want to know what size they are. The size of the DNA can be determined by comparing the position of the DNA band to markers of known sizes. I want to get all of this information into a database, so we don’t have to manually look up the size of the fragment in question.
I could imagine scanning in all the images and then making them into captchas, with lots of redundancy for improved accuracy. But first you’d have to get your porn-surfing/game-playing audience to learn how to read gels. Hmm…
Captcha’s aren’t “useless”. Do you think someone is going to go to the extreme efforts to build an automated circumvention system, which may take them several days/months/years, let alone it might not even work?
Plus, even with this automated system you speak of, they still have to do the extreme work of emailing all these people who are going to do this work for them.. and they may get caught spamming while doing so. And why would they even bother emailing people to verify captcha’s if they could just email the people about their offer they are trying to sell, instead? It’s double the work for nothing.
The point is: it detours people from spamming a significant amount. It’s not like your door locks on the house are useless now that you’ve heard on the news that one person’s house got broken into even though it was locked.
You can say it’s possible for someone to break into your home if you have door locks and a security system. But isn’t it harder for them to break in than if you left the door wide open?
L: Firstly, yes, people *are* going to build automated circumvention systems. If attackers weren’t automating already, CAPTCHAs wouldn’t have been invented. It’s an arms race – the attackers will just automate further.
Secondly, I think you’ve misunderstood how CAPTCHA farms work – “they still have to do the extreme work of emailing all these people who are going to do this work for them.” No, they don’t. I’m not sure why you think CAPTCHA farming involves email. It involves websites. Email has very little to do with it.
CAPTCHAs are not useless. In fact, the “automated system” of which you speak seems to trace to a rather famous blog entry by Cory Doctorow of Boing Boing. In the lovely echochamber of the blogosphere, Cory’s “[s]omeone told me” about the porn-defeats-CAPTCHAs idea has become gospel. That the techies have accepted this as fact is pathetic and laughable. (I thought some of you were trained in the scientific method?!)
http://www.boingboing.net/2004/01/27/solving_and_creating.html
CAPTCHAs can be done better, e.g. by combining visual CAPTCHAs with an audio alternative. Bottom line: it’s about making it harder to abuse a system, and CAPTCHAs do that. There’s no reason they can’t be used in combination with other techniques as well. The near-religious hatred I see of this technology is a joke.
Firstly, Tom, it traces back several months earlier than Cory’s post – back to a newspaper article from 2003, which I’ve linked to in my post and you seem to have entirely missed. But more importantly, you dismiss it as “pathetic and laughable” without giving any argument about *why* it won’t work. As an experienced web techie I can see exactly how it’d work. Now, please stick to actual scientific method and disprove it with something more than bluster about the echo chamber.
Combining visual and audio CAPTCHAs may solve the problem of dealing with partially-sighted users but it still doesn’t cope with the overall usability problem. And “near-religious hatred”? What the hell are you talking about?