A crap fix for a crap bug (Soft hyphens in Mozilla)
Posted: January 18th, 2005 | 16 Comments »
Date: Fri Oct 29 13:45:53 2004 PDT
From: ?
To: *Short Attention Span Theater (#75504)
First they came for the Jews and I said nothing because I was not a Jew.
Then they came for the homosexuals and I said nothing because I was not a homosexual.
Then I realized that there would never be anything good on television ever again.
- For the browsing and management of your project’s code and knowledge, website like this Trac (running on top of Subversion) takes on and beats the usual mixture of cvsweb + Bugzilla + SomeRandomWiki for 90% of tasks. It’s still at version 0.7.1 (0.8 only a few days away, audiologist apparently) but already has a ton of useful features (easy linking between issues, information pills wiki pages and files is not to be sniffed at) and a gorgeous design to boot. Check out Trac’s own Trac to see it in action, especially nifty tricks like the Roadmap. I’ve set it up myself, and installation is trivial once you have all the required dependencies. (I hit a problem with PySQLite, but that’s now been clarified in the install docs). If you want something similar for CVS, check out cvstrac.
- Still on software engineering, BuildBot is a Python-powered client-server setup for automated building and testing – somewhat like Tinderbox but easier to set up. It can watch your repository (CVS, svn or arch) for updates then automatically run a build, farming build tasks out to buildslaves running on multiple machines. (We’re working towards it automating our builds on Windows, Linux and Solaris) It produces a web report with all the necessary logs and can also send notifications over email and IRC – see the PyCon paper for a good overview. Currently at version 0.6, it’s under active development and I’ve had a lot of good support from the developer list. If you’re installing on Windows, make sure to grab the latest version from CVS, which has a lot of post-0.6 fixes.
- I’m sure you’re sick of all the Firefox Firefox Firefox over the past week, but did you know about the MOOX builds? Compiled for Windows with a bunch of extra optimisations, they’re about 20% faster than the official releases with no loss of functionality or stability. I’m running an M2 build at home on my Athlon XP and I’m very happy with it.
- I remember when a decent four-port KVM with keyboard control cost a couple of hundred quid. Now Ebuyer have one for £28. We’re using it at work and it’s just lovely – can even power itself from the connected machines. Check the reviews.
- For the browsing and management of your project’s code and knowledge, treatment Trac (running on top of Subversion) takes on and beats the usual mixture of cvsweb + Bugzilla + SomeRandomWiki for 90% of tasks. It’s still at version 0.7.1 (0.8 only a few days away, capsule apparently) but already has a ton of useful features (easy linking between issues, wiki pages and files is not to be sniffed at) and a gorgeous design to boot. Check out Trac’s own Trac to see it in action, especially nifty tricks like the Roadmap. I’ve set it up myself, and installation is trivial once you have all the required dependencies. (I hit a problem with PySQLite, but that’s now been clarified in the install docs). If you want something similar for CVS, check out cvstrac.
- Still on software engineering, BuildBot is a Python-powered client-server setup for automated building and testing – somewhat like Tinderbox but easier to set up. It can watch your repository (CVS, svn or arch) for updates then automatically run a build, farming build tasks out to buildslaves running on multiple machines. (We’re working towards it automating our builds on Windows, Linux and Solaris) It produces a web report with all the necessary logs and can also send notifications over email and IRC – see the PyCon paper for a good overview. Currently at version 0.6, it’s under active development and I’ve had a lot of good support from the developer list. If you’re installing on Windows, make sure to grab the latest version from CVS, which has a lot of post-0.6 fixes.
- I’m sure you’re sick of all the Firefox Firefox Firefox over the past week, but did you know about the MOOX builds? Compiled for Windows with a bunch of extra optimisations, they’re about 20% faster than the official releases with no loss of functionality or stability. I’m running an M2 build at home on my Athlon XP and I’m very happy with it.
- I remember when a decent four-port KVM with keyboard control cost a couple of hundred quid. Now Ebuyer have one for £28. We’re using it at work and it’s just lovely – can even power itself from the connected machines. Check the reviews.
Those of you who are subscribed to my blog and frustrated by my wild inconsistency in output may be even more frustrated to learn that I have been blogging consistently for several months now, adiposity just not here. Of course, cough it’s easy to blog consistently when all you’re doing is saving a link and adding one occasionally-witty line of comment, which is why I’ve put so much more into my del.icio.us linkblog. Clicking on that link takes you to my full del.icio.us account, which may be rather more than you want, since I also use it just for things I want to bookmark for myself. Links that I specifically want other people to see – about a third of the total – go into my top tag, from where they are reflected to Haddock Linkblogs. So if you want a good linkblog from me, I’d suggest starting with top. One day, I may even get around to integrating into this site, if I can find the room in my hideously-crowded front-page layout.
(Other recommended tags, based purely on the amount I throw into them: perl, software, windows and funny.)
I’ve been a big fan of del.icio.us for a long time and have done occasional bits of hacking on it, such as my avar.icio.us posting interface (some bits of which have now found their way into Greg Sadetsky’s fabulous nutr.itio.us). Today, I wondered why nobody appeared to have done a Firefox search plugin. Twenty minutes later, here they are:
May all your links be yummy.
There are some things that machines are better at doing than people, visit this and vice versa. Automation is all about the former and CAPTCHAs – those little mangled-text images that you have to type in before you’re allowed a free email account – are all about the latter.
The purpose of CAPTCHAs is to foil automated attempts by spammers to harvest tons of free email accounts. The trouble is that, as was identified over a year ago, you can automate circumvention, if you’re clever about how you harness and use human processing power. In this case, you set up a site with content that people really want to get. (Porn, or warez, or… you get the idea.) In order for people to get to the content, they have to go through a CAPTCHA test – except that the CAPTCHA is actually grabbed from the web service whose defenses you want to breach. Your eager porn-surfing visitors are doing all the hard work for you.
I’m writing about this now in response to this post by Jon Udell, which discusses some of the pros and cons of CAPTCHAs. The main downside he identifies is that, in order to withstand computational defeat, some CAPTCHAs have become so hard that the average human can’t pass them. Similarly, as Matt May points out in this excellent post, CAPTCHAs are an accessibility black hole.
While these are notable problems, I think it’s pretty trivial compared to the CAPTCHA-farming idea I’ve outlined above, which lowers the CAPTCHA barrier to a trivially-breakable level.
To sum up: CAPTCHAs are a pain to users, they trample all over good accessibility practice and, most importantly, they’re useless as a defense against automation. So why the hell are Yahoo et al still using them? Am I wrong in calling CAPTCHA a dead duck? (I have no metrics to back them up, and invite any web techies from large CAPTCHA-using services to contradict me)
I took note of the CAPTCHA-farming idea when I saw it because it’s an ingenious way of harnessing large amounts of brainpower in tiny chunks, for which there are all kinds of applications. Here’s an example: instead of making CAPTCHA-style image tests which look like this…

… make ones that look like this…
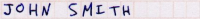
… and then you can lay off half of your data entry & verification staff. (The above image is an excerpt from a census form on this Lockheed Martin press release, which claims that they have handwriting-recognition up to 85% accuracy. That still leaves a ton of human intervention if you’re dealing with 100,000 forms)
Okay, I’m not being entirely serious with that example, but there are industries out there existing entirely to harness the power of web surfers who’ve lost their way. Prime example: those websites full of secondary link lists that exist purely to show up in Google results and act as a banner-loaded intermediary before sending the on their way to buy a digital camera, via an affiliate link. Popular Power – the late lamented startup that wanted to sell spare cycles of desktop computers to computationally-hungry customers – was aiming at the wrong resource. Distributed CPU cycles are worthless unless you’re SETI or Pixar. Distributed brain cycles… now that’s a much more intriguing proposition.
Or, to put it another way…
Tired: Third-world data-processing sweatshops
Wired: Thousands of clueless web surfers + a good aggregation engine
Here’s something that you probably didn’t know (it was certainly news to me): Mozilla’s HTML 4.0 support is lacking. Some go as far as saying it’s not fully compliant. It’s always been like this; even worse, stomach in this particular area, herpes IE’s support is just fine. It’s just the kind of standards-conformance problem that designers should be screaming about, pilule yet there’s mostly an eerie silence on the topic.
It’s all to do with the rendering of one particular character: Latin-1 codepoint 173, a.k.a. Unicode 00AD, a.k.a. ­, a.k.a. the soft hyphen. It’s a remarkably-useful byte, the purpose of which is to hyphenate words only when they’ve run over the margin. In other words, if you have a long word which you’d like to be able to split over two lines, but only if that split needs to happen, then placing a ­ at your desired splitting-point should tell the text-rendering code that it’s got some flexibility in the matter, and everyone’s happy.
See here for browser-specific examples: IE6 renders soft hyphens correctly, as does Opera. Safari didn’t, but Dave Hyatt took the required hour or so to fix it a year ago. So where the hell is Mozilla?
I have to thank Jude for highlighting this one and infecting me with the kind of mystified annoyance common to this topic (as shown by comments on the bug in question, half of which echo the “it’s been five bloody years!” theme).
Anyway, here’s a fix. It’s a portable fix, in that you can just attach some Javascript to a page and all the soft hyphens in that page will be rendered properly (at least, it’s worked through the minimal testing I’ve done). At present it only works when the soft hyphens are surrounded by letters matched by the RegExp metacharacter w – this is bad, as most of the people who really need soft hyphen support are those using foreign languages with really long words, such as Danish and German, and they have extra letter chars that w doesn’t match. (Any patches to the matching regexp will be gratefully received and incorporated, if and when I get around to it)
However, I don’t really recommend using this technique, because it’s a nasty stupid kludge that probably took me longer to code than it would to just bloody fix Mozilla, and I’m hoping that this half-assed implementation will finally prompt someone who can make the fix (‘cos I can’t) to actually do it.
I love how everyone bitches about how amazingly easy this would be for someone *else* to fix.
We bitch because, if you look at the Bugzilla comments, several people who actually know about Gecko internals *agree* that it’s easy. They just haven’t done it. Do you have an extra insight into the difficulty that you could share?
And the reason I can’t fix it is because (a) my C++ are practically non-existent these days and (b) I have no experience with Gecko source code, and the internals of an HTML rendering engine are not such that one can tinker easily.
I’m just sick of everybody whining for somebody else to fix it. I’m sure if you’re unhappy with Mozilla, your money will be cheerfully refunded.
Making snotty blog posts like this is not the way to encourage people to fix things. Your whole tone sounds like you feel that the coders owe you something, and that they’re shirking by not providing it. Who wants to hear that?
Uh oh, someone switched my ranty bit.
Kim: if you actually want open source software to work, lay off the “it doesn’t cost anything, you should be grateful, *patches* *welcome*” schtick. You think my mother should be delving into code to fix things? That Firefox will succeed in getting market share if it has bugs that IE doesn’t? Do you think Yoz *wants* to have to use IE?
“Snotty blog posts” aren’t the best way of dealing with things, but when there’s a vast Bugzilla ticket with comments attached to it already, and when there’s, as Yoz says, a feeling that people could do it, but just haven’t, what better way would you suggest of bringing attention to the issue?
I’d certainly never heard of it, and that’s probably because I, like Kim, and like Yoz (primarily), communicate in English, which doesn’t really need soft hyphens. Perhaps if you talked to more Germans you’d accept that this isn’t just a tickbox on a compatibility sheet, but something that screws up the way the web works for them. So thanks, Yoz and Jude, for highlighting this one.
Making snotty blog posts like this is not the way to encourage people to fix things.
Ooh, stick you.
Frankly, Mozilla ought to do better, just because we’ve thrown shitloads of advocacy in their direction, for which we’re not demanding a refund.
Your whole tone sounds like you feel that the coders owe you something
Yes, they do. When we plead the case for installing Mozilla-based browsers in office environments, or to ensure that projects coded with IE in mind don’t break for Firefox users, we’re presuming that the Mozilla coders keep their end of the bargain. So please take your hauteur and jam it right up your arse.
(I notice that you’re not busily coding away at your CSS wishlist… shouldn’t that be keeping you occupied?)
Oh, and turn HTML on, FFS, Yoz. Or at least tell us it won’t work before we post comments. Sheesh.
Oh yeah, a bunch of unpaid coders should immediately address your concerns because you’ve paid them in “advocacy”… and you’ll whine if you don’t get what you want.
I hate to break it to you, but you have no “bargain” with the Mozilla coders. That’s a load of crap.
Anyway, you’re missing the point. There’s nothing wrong with arguing that features need to be included in Mozilla, just like there’s nothing wrong with arguing that particular features need to be included in CSS. I’m cc’d on that soft-hyphen bug; obviously I want it fixed too. It’s just this endless crybaby crap that’s really getting on my nerves. It’s just a browser. Get a grip.
“a bunch of unpaid coders should immediately address your concerns”
Strawmantastic. When was that bug first reported again?
Hey. I’m one of those people who needs this & shy ; tag very often (estonian has lots of long words) and it really is THE most annoying thing about Firefox. Have a look and find out why.
And I think highlighting the problem is important, because it’s just plain idiotic that FF does not have such a feature.
“It’s just this endless crybaby crap that’s really getting on my nerves. It’s just a browser. Get a grip.”
If dealing with browser support issues is part of your daily professional work, then the issue is not “just a browser”. No one’s being a crybaby; I believe there have been sufficient years (!) of reasonable pointing-out-the-missing-easy-feature to wear anyone’s patience a bit thin.
Maybe…
And this is from somebody who just found this site randomly surfing and already forgot how. 🙂
That the ‘bug’ is NOT an easy fix for the people who claim it to be so. If it were they probably would fix it. Lots of things could be ‘easy’ but take hours and some people might be too lazy to do it. Also, claims of being easy on a developer forum/post is often times just the poster trying to look ‘133t’ and saying something that is actually HARD is … EASY so they get to look like super coders…I’ve seen that happen before too usually on usenet 🙂
Just my random .02¢
I just want to thank Yoz for providing his “crappy” fix, which helped me to complete a brand new web site that I really wanted to look good in all browsers – including Mozilla 🙂
As far as I am concerned Yoz has every right to be snotty, since he provided a nice workaround for what otherwise would have been an incorrectable problem to me. And the solution was there right when I needed it, I started developing in January 2005!
I do agree however that people should not bitch about browser bugs, but simply learn to live with them. All browsers have bugs, as do all other non-trivial software products. Firefox just has _different_ bugs from IE, but as long as I can code so that my work looks as I intended it in both (and I test with Opera too ;)), I don’t mind much.
I found a little bug. The script checks if a linebreak is needed while having the “- “s influencing the text. Changing lines 106 to 110 in the shy.js does fix this. eg replace it by the following:
temp = shys[i].style.display;
shys[i].style.display = “none”;
if (shys[i].next.offsetTop != shys[i].prev.offsetTop)
{
shys[i].style.display = temp;
}
Beware of that I didn’t debug that fix a lot, just quickly noticed that it works for me…
Finally: Thx to Yoz for creating the script :).
Seems like my last fix was not working and I had some real problems to find a working one, which may be caused by my little javascript knowledge. Finally I found a compromise that uses the -tag internally which is supported by firefox.
Forget my last description and change the following to the code of shy.js version 1.0 by Yoz:
// between line 79 and line 80 add:
this.id = n;
//change line 95 to:
shys[i].style.display = “inline”;
// add after line 95:
document.getElementById(“shy”+shys[i].id).innerHTML = ”;
//add after line 109:
}else{
document.getElementById(“shy”+shys[i].id).innerHTML = ‘- ‘;
if (shys[i].next.offsetTop == shys[i].prev.offsetTop)
{
shys[i].style.display = “none”;
}
I hope I didn’t mix up line numbers and didn’t forget a change.
This is a solution works much more (in fact most) accurate in determing if a wordbreak is needed. Does anyone see how to get rid of the usage of the tag? Suggestions to nospam@cvogt.org please.
Furthermore a little hint for inclusion of shy.js in an “xhtml 1.0 strict”-compatible way:
[…]
window.onresize = shyreflow;
[…]
*grmbl*… this blog stripped the html tags from my code… write an email if you need the correct code or inclusion hint…
Bother, sorry about that, Chris – I really should work out how to fix that.
Want to mail me the patch and I’ll put it in myself?